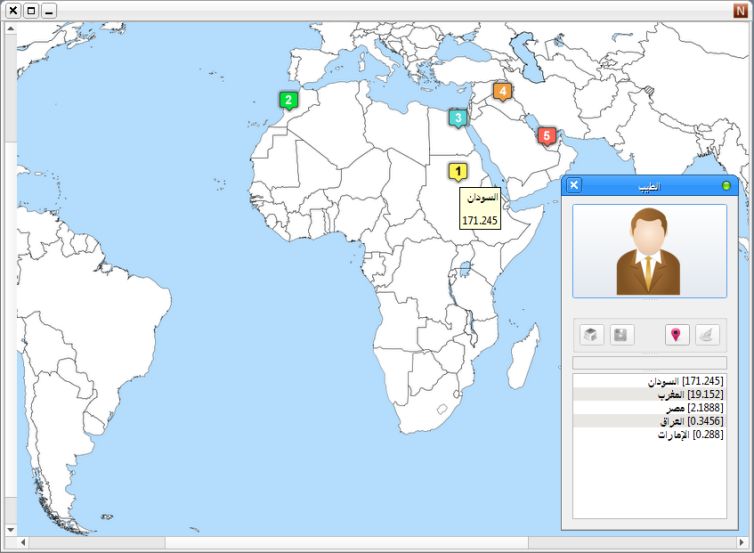
|
|
 دعوة لتجربة واختبار برنامج التصنيف الجغرافي للأسماء دعوة لتجربة واختبار برنامج التصنيف الجغرافي للأسماء
|
دعوة لتجربة واختبار برنامج التصنيف الجغرافي للأسماء
اسم البرنامج: MAPSOno Arabic Names Indexer/Geolocater
طبيعة البرنامج:
English: http://www.kalmasoft.com/KMAPS/molindx.htm
عربي:http://www.kalmasoft.com/KMAPS/amolindx.htm
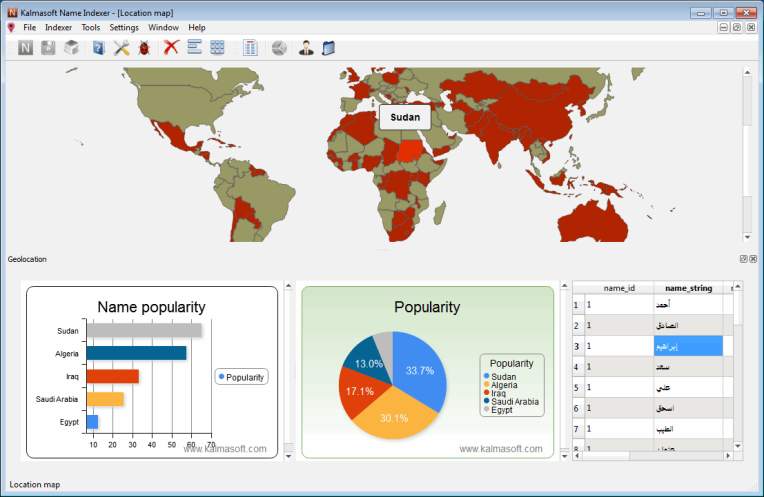
الغرض: اكتشاف النتائج غير المنطقية للأسماء المصنفة بواسطة البرنامج.
---------------------------
طريقة التثبيت:
1- قم بتنزيل الملف المضغوط الخاص بمكتبة كلماسوفت، فك الضغط ثم ثبت المكتبة.
2- قم بتنزيل الملف المضغوط للبرنامج وفك الضغط ثم ثبت البرنامج في نفس الدليل السابق للمكتبة
مكتبة كلماسوفت
http://www.kalmasoft.com/support/KLibrary.rar ---------------------------
صفحة التنزيل (Download)
English:http://www.kalmasoft.com/KMAPS/spmolix.htm
عربي: http://www.kalmasoft.com/KMAPS/aspmolix.htm ---------------------------
دليل المستخدم (تثبيت واستخدام): (Manual)
English: http://www.kalmasoft.com/support/DOCMOLIndex.pdf
عربي: http://www.kalmasoft.com/support/DOCAMOLIndex.pdf ---------------------------
الرد بالملاحظات (reporting):
الرد هنا في البوست أو في الخاص بالآتي: الاسم الذي تم إدخاله ورأي المستخدم في انتماء الاسم إلى جغرافية غير المقترحة بواسطة البرنامج
خالص الشكر
|
|
 
|
|
|
|
|
|
|
|
Re: دعوة لتجربة واختبار برنامج التصنيف الجغرافي للأسماء (Re: حاتم إبراهيم)
|
فكرة البرنامج:
تقوم على مسألة المقارنات الديمغرافية للاسم العربي (وغير العربي) بناء على قواعد بيانات معالجة احصائياً.
النسخة الحالية لا تشمل كل الأسماء المعروفة وهي معدة بطريقة محددة بحيث لا تشمل الأسماء المميزة في المنطقة الجغرافية (القطر)،
بل تعمل بناء على شيوع الاسم قياسأ بالاسم الأول والأخير، هذا يعني أن الأسلوب المتبع في السودان (lineage genealogy) ربما
يعطي نتائج غير متوقعة.
البرنامج يمكن ضبطه للعمل بواجهة عربية أو إنجليزية (الفرنسية والألمانية لاحقاً)، يمكن أيضاً اختيار واحد من خمسة استايلات للواجهة
أو واحد من ثلاث استايلات للطباعة.
لا يعمل البرنامج بدون ضبطه مسبقاً لجلب معلومات الأسماء من قاعدة البيانات المدمجة معه (أنظر دليل المستخدم، 9 صفحات فقط)
| |
|
|
|
|
|
|
|
|
|
Re: دعوة لتجربة واختبار برنامج التصنيف الجغرافي للأسماء (Re: حاتم إبراهيم)
|
ملاحظات حول البرنامج:
البرنامج (في نسخته الكاملة) يغطي الأسماء في حوالي 30 دولة بدلاً عن الخمسة المعلنة في النسخة التجريبية، ( 17 دولة عربية+ 5 دول شبه عربية "جيبوتي، السودان، جزر القمر، الصومال، إرتريا + بقية الدول التي تستعمل أسماء عربية ضمن المكون المحلي " إيران، باكستان، ماليزيا، أفغانستان ...").
الوضع الطبيعي هو محاولة الحصول على الدولة الأعلى نسبة من بين الدول المقترحة عبر منطق إحصائي معقد وتتداخل فيه عوامل مختلفة ومتغيرة، مثل المفاضلة بين تميز الاسم (uniqueness) وشيوعه (popularity) الاسم "الجاك" كنموذج مميز في السودان لكنه غير شائع بينما "عوض" مميز وشائع و "إبراهيم" شائع وغير مميز و "عثمان" غير شائع وغير مميز، خلافاً لما تروج له بعض الدوائر الإعلامية.
حالة أخرى لأسماء تبدو احصائياً مميزة ظاهرياً (falsely positive) مثل "نواف" و"صدام" في السودان وغيرها من الأسماء الوافدة، هذه يتعامل مها البرنامج بالتحقق من عامل الزمن.
ملحوظة أخيرة، البرنامج في نسخته التجريبية غير صارم في التعامل مع هيئة الاسم الإملائية (orthography) ويقبل بكل بساطة أي مدخلات، هذا لتيسير التعامل معه للمبتدئين، لكنه في أصل البرنامج (النسخة الكاملة) يطبق وظيفة المطابقة الظنية (fuzzy match) وذلك بحسبان أن المقصود "أحمد" بدلاً عن "احمد" و "مصطفى" بدلاً عن "مصطفي" و "إبراهيم" بدلاً عن "أبراهيم" وهكذا.
| |
|
|
|
|
|
|
| |


 حاتم إبراهيم
حاتم إبراهيم
 Hani Arabi Mohamed
Hani Arabi Mohamed